mirror of
https://github.com/wezm/wezm.net.git
synced 2025-04-09 05:00:42 +00:00
Compare commits
4 commits
07b8cc089f
...
ac6bac0903
| Author | SHA1 | Date | |
|---|---|---|---|
| ac6bac0903 | |||
| 125d800bbc | |||
| f68249c354 | |||
| 3acf555ada |
4 changed files with 303 additions and 4 deletions
v2/content/posts/2024
|
|
@ -27,7 +27,7 @@ born.
|
|||
|
||||
So far I've published four projects to it, all of which are open-source.
|
||||
|
||||
## Titlecase
|
||||
### Titlecase
|
||||
|
||||
[Titlecase] is one of the earliest Rust crates I wrote. The first commit was in
|
||||
2017. It converts text into title case. Specifically it uses [a style described
|
||||
|
|
@ -48,7 +48,7 @@ I have compiled it to WebAssembly so that it can be [used online][Titlecase].
|
|||
|
||||
{{ figure(image="posts/2024/7bit-projects/Convert%20Text%20to%20Titlecase%20-%207bit.org.png", link="https://7bit.org/titlecase/", border=1, width="739", alt='Screenshot of the Titlecase web page showing the result of converting the text ‘an iPhone review: "our take in 10 minutes"’ to title case with the tool. The resulting text is ‘An iPhone Review: "Our Take in 10 Minutes"’.', caption="Screenshot of the Titlecase web page") }}
|
||||
|
||||
## RSS Please
|
||||
### RSS Please
|
||||
|
||||
[RSS Please] is a tool to generate RSS feeds from web pages. It uses
|
||||
CSS selectors to extract parts of the page to generate the feed from.
|
||||
|
|
@ -56,7 +56,7 @@ It's implemented as a command line tool in Rust.
|
|||
|
||||
{{ figure(image="posts/2024/7bit-projects/RSS%20Please.png", link="https://rsspls.7bit.org/", alt="Screenshot of the RSS Please website. It has a teal backgound and features a screenshot of the tool running in a terminal. There is an orange RSS logo in the top left and download button in the bottom left.", caption="Screenshot of the RSS Please website") }}
|
||||
|
||||
## Dew Point Forecast
|
||||
### Dew Point Forecast
|
||||
|
||||
[Dew Point Forecast] provides weather forecasts that include the dew point. The
|
||||
dew point relates to how humid it feels. It's a better measure than relative
|
||||
|
|
@ -69,7 +69,7 @@ web framework.
|
|||
|
||||
{{ figure(image="posts/2024/7bit-projects/Dew%20Point%20-%20Forecast%20for%20Brisbane%20City.png", link="https://dewpoint.7bit.org/", border=1, width="739", alt="Screenshot of the dew point forecast for Brisbane, Australia. There are boxes for current conditions, Sat 4 May, Sun 5 May, and Mon 6 May. Each box contains values for temperature, dew point, sunrise, sunset, UV index, and relative humidity.", caption="Dewpoint forecast for Brisbane") }}
|
||||
|
||||
## MacBinary
|
||||
### MacBinary
|
||||
|
||||
[MacBinary] allows inspection and downloading of individual components in
|
||||
MacBinary encoded files that were used by the classic Mac OS. It's available as
|
||||
|
|
@ -80,6 +80,10 @@ post](@/posts/2023/rust-classic-mac-os-app/index.md#macbinary).
|
|||
|
||||
{{ figure(image="posts/2024/7bit-projects/Decode%20MacBinary%20Online%20-%207bit.org.png", link="https://7bit.org/macbinary/", border=1, width="739", alt="Screenshot of the MacBinary webpage. It is showing the parsed information from a file called 'bbedit_lite_612.smi_.bin'. Several resources are lists such as 'BNDL', and 'CODE'.", caption="Screenshot of the MacBinary web page") }}
|
||||
|
||||
### Comments
|
||||
|
||||
* [Fediverse](https://mastodon.decentralised.social/@wezm/112391817575822540)
|
||||
|
||||
[RSS Please]: https://rsspls.7bit.org/
|
||||
[Dew Point Forecast]: https://dewpoint.7bit.org/
|
||||
[Titlecase]: https://7bit.org/titlecase/
|
||||
|
|
|
|||
{kind=link}
Binary file not shown.
|
After 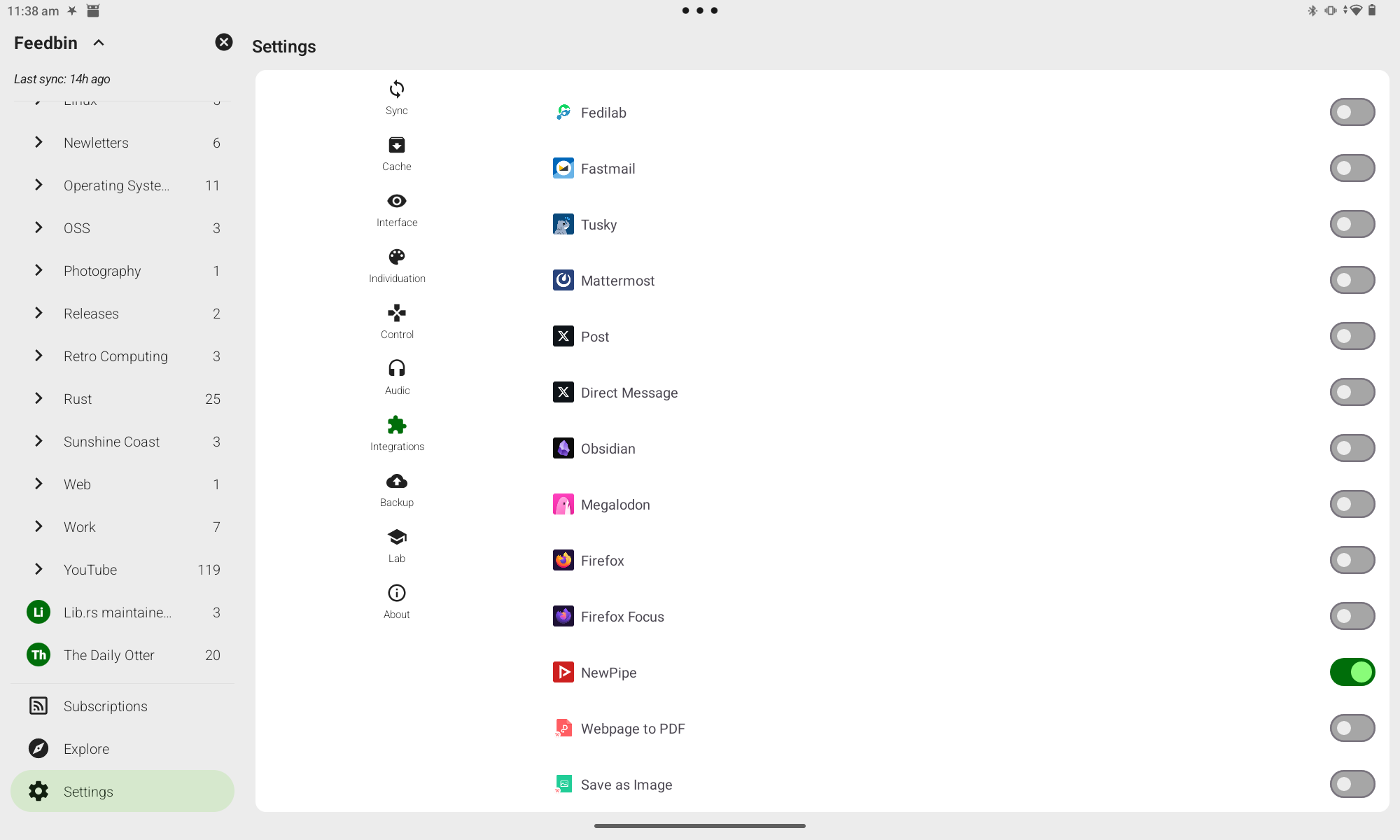
(image error) Size: 108 KiB |
BIN
v2/content/posts/2024/youtube-subscriptions-opml/feedme.png
Normal file
BIN
v2/content/posts/2024/youtube-subscriptions-opml/feedme.png
Normal file
{kind=link}
Binary file not shown.
|
After 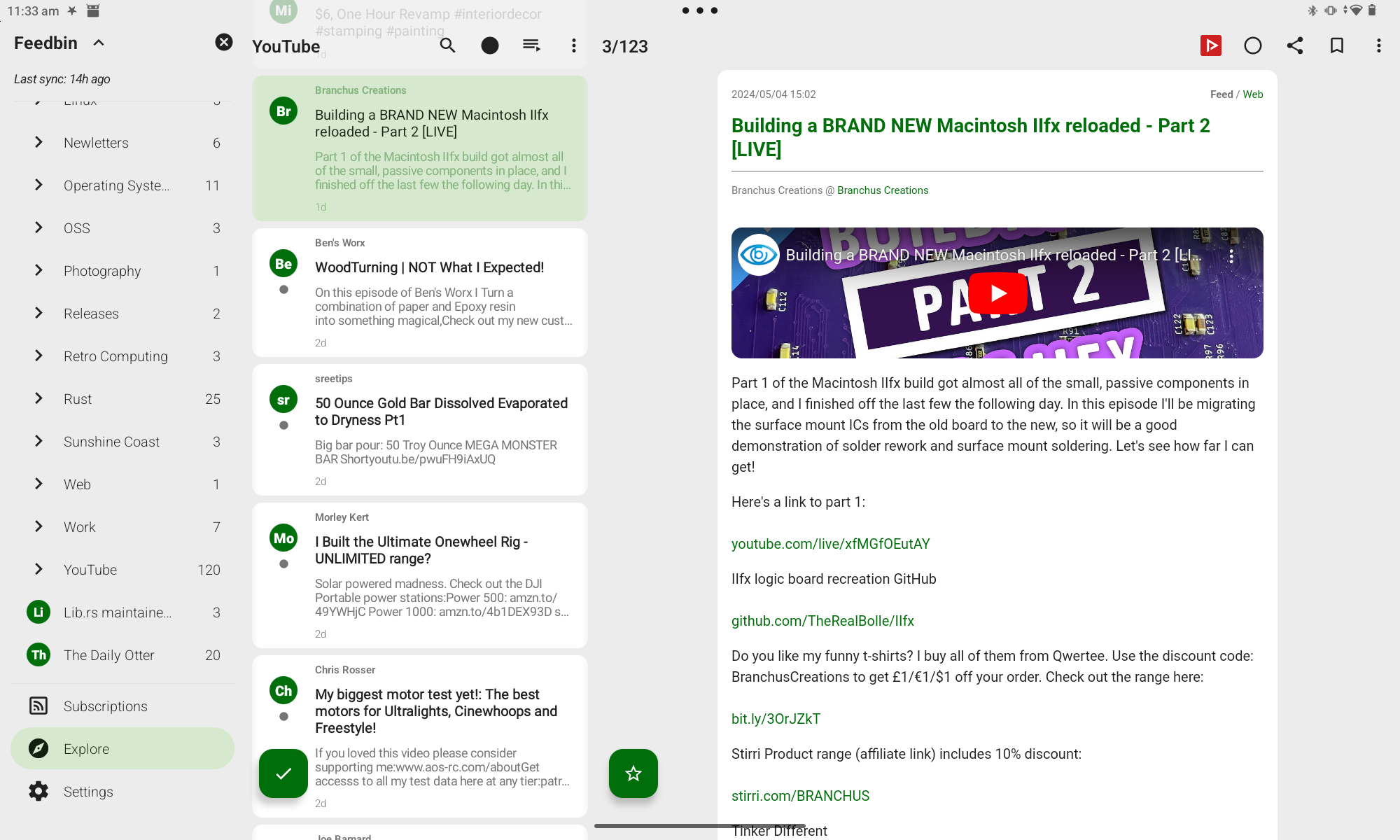
(image error) Size: 486 KiB |
295
v2/content/posts/2024/youtube-subscriptions-opml/index.md
Normal file
295
v2/content/posts/2024/youtube-subscriptions-opml/index.md
Normal file
|
|
@ -0,0 +1,295 @@
|
|||
+++
|
||||
title = "Exporting YouTube Subscriptions to OPML and Watching via RSS"
|
||||
date = 2024-05-06T10:38:22+10:00
|
||||
|
||||
#[extra]
|
||||
#updated = 2024-02-21T10:05:19+10:00
|
||||
+++
|
||||
|
||||
This post describes how I exported my 500+ YouTube subscriptions to an OPML
|
||||
file so that I could import them into my RSS reader. I go into fine detail
|
||||
about the scripts and tools I used. If you just want to see the end result the
|
||||
code is in [this repository][repo], which describes the steps needed to run it.
|
||||
|
||||
I was previously a YouTube Premium subscriber but I cancelled it when they
|
||||
jacked up the already high prices. Since then I've been watching videos in
|
||||
[NewPipe] on my Android tablet or via an [Invidious] instance on real
|
||||
computers.
|
||||
|
||||
<!-- more -->
|
||||
|
||||
To import my subscriptions into NewPipe I was able to use the
|
||||
`subscriptions.csv` file included in the Google Takeout dump of my YouTube
|
||||
data. This worked fine initially but imposed some friction when adding new
|
||||
subscriptions.
|
||||
|
||||
If I only subscribed to new channels in NewPipe they were only
|
||||
accessible on my tablet. If I added them to YouTube then I had to remember to
|
||||
also add them in NewPipe, which was inconvenient if I wasn't using the tablet
|
||||
at the time. Inevitably the subscriptions would drift out of sync and I would have to
|
||||
periodically re-import the subscriptions from YouTube into NewPipe. This was
|
||||
cumbersome as it doesn't seem to have a way to do this incrementally. Last time
|
||||
I had to nuke all its data in order to re-import.
|
||||
|
||||
To solve these problems I wanted to manage my subscriptions in my RSS reader,
|
||||
[Feedbin]. This way Feedbin would track my subscriptions and new/viewed videos
|
||||
in a way that would sync between all my devices. Notably this is possible
|
||||
because Google actually publishes an RSS feed for each YouTube channel.
|
||||
|
||||
To do that I needed to export all my subscriptions to an OPML file that Feedbin
|
||||
could import. I opted to do that without requesting another Google Takeout dump
|
||||
as they take a long time to generate and also result in multiple gigabytes of
|
||||
archives I have to download (it includes all the videos I've uploaded to my
|
||||
personal account) just to get at the `subscriptions.csv` file within.
|
||||
|
||||
### Generating OPML
|
||||
|
||||
I started
|
||||
by visiting my [subscriptions page][subscriptions] and using some JavaScript to
|
||||
generate a JSON array of all the channels I am subscribed to:
|
||||
|
||||
```javascript
|
||||
copy(JSON.stringify(Array.from(new Set(Array.prototype.map.call(document.querySelectorAll('a.channel-link'), (link) => link.href))).filter((x) => !x.includes('/channel/')), null, 2))
|
||||
```
|
||||
|
||||
This snippet:
|
||||
|
||||
- queries the page for all channel links
|
||||
- gets the link URL of each matching element
|
||||
- Creates a `Set` from them to de-duplicate them
|
||||
- Turns the set back into an `Array`
|
||||
- filters out ones that contain `/channel/` to exclude some links like Trending
|
||||
that also appear on that page
|
||||
- Turns the Array into pretty printed JSON
|
||||
- Copies it to the clipboard
|
||||
|
||||
With the list of channel URLs on my clipboard I pasted this into a
|
||||
`subscriptions.json` file. The challenge now was that these URLs were of the
|
||||
channel pages like:
|
||||
|
||||
`https://www.youtube.com/@mooretech`
|
||||
|
||||
but the RSS URL of a channel is like:
|
||||
|
||||
`https://www.youtube.com/feeds/videos.xml?channel_id=<CHANNEL_ID>`,
|
||||
|
||||
which means I needed to determine the channel id for each page. To do that
|
||||
without futzing around with Google API keys and APIs I needed to download the
|
||||
HTML of each channel page.
|
||||
|
||||
To do that I generated a config file for `curl` from the JSON file:
|
||||
|
||||
jaq --raw-output '.[] | (split("/") | last) as $name | "url \(.)\noutput \($name).html"' subscriptions.json > subscriptions.curl
|
||||
|
||||
[jaq] is an alternative implementation of [jq] that I use. This `jaq` expression does the following:
|
||||
|
||||
- `.[]` iterate over each element of the `subscriptions.json` array.
|
||||
- `(split("/") | last) as $$name` split the URL on `/` and take the last element, storing it in a variable called `$name`.
|
||||
- for a URL like `https://www.youtube.com/@mooretech` this stores `@mooretech` in `$name`.
|
||||
- `"url \(.)\noutput \($$name).html"` generates the output text interpolating the channel page url and channel name.
|
||||
|
||||
This results in lines like this for each entry in `subscriptions.json`, output
|
||||
to `subscriptions.curl`:
|
||||
|
||||
url https://www.youtube.com/@mooretech
|
||||
output @mooretech.html
|
||||
|
||||
I then ran `curl` against this file to download all the pages:
|
||||
|
||||
curl --location --output-dir html --create-dirs --rate 1/s --config subscriptions.curl
|
||||
|
||||
- `--location` tells curl to follow redirects, for some reason three of my subscriptions redirected to alternate names when accessed.
|
||||
- `--output-dir` tells curl to output the files into the `html` directory.
|
||||
- `--create-dirs` tells curl to create output directories if they don't exist (just the `html` one in this case).
|
||||
- `--rate 1/s` tells curl to only download at a rate of 1 page per second—I was concerned YouTube might block me if I requested the pages too quickly.
|
||||
- `--config subscriptions.curl` tells curl to read additional command line arguments from the `subscriptions.curl` file generated above.
|
||||
|
||||
Now that I had the HTML for each channel I needed to extract the channel id
|
||||
from it. While I was processing each HTML file I also extracted the channel
|
||||
title for use later. For each HTML file I ran this script on it. I called the
|
||||
script `generate-json-opml`:
|
||||
|
||||
```sh
|
||||
#!/bin/sh
|
||||
|
||||
set -eu
|
||||
|
||||
URL="$1"
|
||||
NAME=$(echo "$URL" | awk -F / '{ print $NF }')
|
||||
HTML="html/${NAME}.html"
|
||||
CHANNEL_ID=$(scraper -a content 'meta[property="og:url"]' < "$HTML" | awk -F / '{ print $NF }')
|
||||
TITLE=$(scraper -a content 'meta[property="og:title"]' < "$HTML")
|
||||
XML_URL="https://www.youtube.com/feeds/videos.xml?channel_id=${CHANNEL_ID}"
|
||||
|
||||
json_escape() {
|
||||
echo "$1" | jaq --raw-input .
|
||||
}
|
||||
|
||||
JSON_TITLE=$(json_escape "$TITLE")
|
||||
JSON_XML_URL=$(json_escape "$XML_URL")
|
||||
JSON_URL=$(json_escape "$URL")
|
||||
|
||||
printf '{"title": %s, "xmlUrl": %s, "htmlUrl": %s}\n' "$JSON_TITLE" "$JSON_XML_URL" "$JSON_URL" > json/"$NAME".json
|
||||
```
|
||||
|
||||
Let's break that down:
|
||||
|
||||
- The channel URL is stored in `URL`.
|
||||
- The channel name is determined by using `awk` to split the URL on `/` and take the last element.
|
||||
- The path to the downloaded HTML page is stored in `HTML`.
|
||||
- The channel id is determined by finding the `<meta>` tag in the html with a `property` attribute of `og:url` (the [OpenGraph metadata][OpenGraph] URL property). This URL is again split on `/` and the last element stored in `CHANNEL_ID`.
|
||||
- Querying the HTML is done with a tool called [scraper] that allows you to use CSS selectors to extract parts of a HTML document.
|
||||
- The channel title is done similarly by extracting the value of the `og:title` metadata.
|
||||
- The URL of the RSS feed for the channel is stored in `XML_URL` using `CHANNEL_ID`.
|
||||
- A function to escape strings destined for JSON is defined. This makes use of `jaq`.
|
||||
- `TITLE`, `XML_URL`, and `URL` are escaped.
|
||||
- Finally we generate a JSON object with the title, URL, and RSS URL and write it into a `json` directory under the name of the channel.
|
||||
|
||||
Ok, almost there. That script had to be run for each of the channel URLs.
|
||||
First I generated a file with just a plain text list of the channel URLs:
|
||||
|
||||
jaq --raw-output '.[]' subscriptions.json > subscriptions.txt
|
||||
|
||||
Then I used `xargs` to process them in parallel:
|
||||
|
||||
xargs -n1 --max-procs=$(nproc) --arg-file subscriptions.txt --verbose ./generate-json-opml
|
||||
|
||||
This does the following:
|
||||
|
||||
- `-n1` read one line from `subscriptions.txt` to be passed as the argument to `generate-json-opml`.
|
||||
- `--max-procs=$(nproc)` run up the number of cores my machine has in parallel.
|
||||
- `--arg-file subscriptions.txt` read arguments for `generate-json-opml` from `subscriptions.txt`.
|
||||
- `--verbose` show the commands being run.
|
||||
- `./generate-json-opml` the command to run (this is the script above).
|
||||
|
||||
Finally all those JSON files need to be turned into an OPML file. For this I
|
||||
used Python:
|
||||
|
||||
```python
|
||||
#!/usr/bin/env python
|
||||
|
||||
import email.utils
|
||||
import glob
|
||||
import json
|
||||
import xml.etree.ElementTree as ET
|
||||
|
||||
opml = ET.Element("opml")
|
||||
|
||||
head = ET.SubElement(opml, "head")
|
||||
title = ET.SubElement(head, "title")
|
||||
title.text = "YouTube Subscriptions"
|
||||
dateCreated = ET.SubElement(head, "dateCreated")
|
||||
dateCreated.text = email.utils.formatdate(timeval=None, localtime=True)
|
||||
|
||||
body = ET.SubElement(opml, "body")
|
||||
youtube = ET.SubElement(body, "outline", {"title": "YouTube", "text": "YouTube"})
|
||||
|
||||
for path in glob.glob("json/*.json"):
|
||||
with open(path) as f:
|
||||
info = json.load(f)
|
||||
ET.SubElement(youtube, "outline", info, type="rss", text=info["title"])
|
||||
|
||||
ET.indent(opml)
|
||||
print(ET.tostring(opml, encoding="unicode", xml_declaration=True))
|
||||
```
|
||||
|
||||
This generates an OPML file (which is XML) using the ElementTree library. The
|
||||
OPML file has this structure:
|
||||
|
||||
```xml
|
||||
<?xml version='1.0' encoding='utf-8'?>
|
||||
<opml>
|
||||
<head>
|
||||
<title>YouTube Subscriptions</title>
|
||||
<dateCreated>Sun, 05 May 2024 15:57:23 +1000</dateCreated>
|
||||
</head>
|
||||
<body>
|
||||
<outline title="YouTube" text="YouTube">
|
||||
<outline title="MooreTech" xmlUrl="https://www.youtube.com/feeds/videos.xml?channel_id=UCLi0H57HGGpAdCkVOb_ykVg" htmlUrl="https://www.youtube.com/@mooretech" type="rss" text="MooreTech" />
|
||||
</outline>
|
||||
</body>
|
||||
</opml>
|
||||
```
|
||||
|
||||
It does the following:
|
||||
|
||||
- Generates the top level OPML structure.
|
||||
- For each JSON file, read and parse the JSON and then use that to generate an `outline` entry for that channel.
|
||||
- Indent the OPML document.
|
||||
- Write it to stdout using a Unicode encoding with an XML declaration (`<?xml version='1.0' encoding='utf-8'?>`).
|
||||
|
||||
Whew that was a lot! With the OMPL file generated I was finally able to import
|
||||
all my subscriptions into Feedbin.
|
||||
|
||||
All the code is available in [this
|
||||
repository](https://forge.wezm.net/wezm/youtube-to-opml). In practice I used a
|
||||
`Makefile` to run the various commands so that I didn't have to remember them.
|
||||
|
||||
### Watching videos from Feedbin
|
||||
|
||||
Now that Feedbin is the source of truth for subscriptions, how do I actually
|
||||
watch them? I set up the [FeedMe] app on my Android tablet. In the settings I
|
||||
enabled the NewPipe integration and set it to open the video page when tapped:
|
||||
|
||||
{{ figure(image="posts/2024/youtube-subscriptions-opml/feedme-settings.png", link="posts/2024/youtube-subscriptions-opml/feedme-settings.png", alt='Screenshot of the FeedMe integration settings. There are lots of apps listed. The entry for NewPipe is turned on.', caption="Screenshot of the FeedMe integration settings") }}
|
||||
|
||||
Now when viewing an item in FeedMe there is a NewPipe button that I can tap to
|
||||
watch it:
|
||||
|
||||
{{ figure(image="posts/2024/youtube-subscriptions-opml/feedme.png", link="posts/2024/youtube-subscriptions-opml/feedme.png", alt='Screenshot of FeedMe viewing a video item. In the top left there is a NewPipe button, which when tapped opens the video in NewPipe.', caption="Screenshot of FeedMe viewing a video item") }}
|
||||
|
||||
### Closing Thoughts & Future Work
|
||||
|
||||
Could I have done all the processing to generate the OPML file with a single
|
||||
Python file? Yes, but I rarely write Python so I preferred to just cobble
|
||||
things together from tools I already knew.
|
||||
|
||||
Should I ever become a YouTube Premium subscriber again I can continue to
|
||||
use this workflow and watch the videos from the YouTube embeds that
|
||||
Feedbin generates, or open the item in the YouTube app instead of NewPipe.
|
||||
|
||||
At some point I'd like to work out how to get Feedbin to filter out YouTube
|
||||
Shorts. It has the ability to automatically filter items matching any of the
|
||||
supported [search syntax][feedbin-search] but I'm not sure if Shorts are
|
||||
easily identifiable.
|
||||
|
||||
Lastly, what about desktop usage? When I'm on a real computer I read my RSS via
|
||||
the Feedbin web app. It supports [custom sharing
|
||||
integrations][feedbin-sharing]. In order to open a video on an Invidious
|
||||
instance I need to rewrite it from a URL like:
|
||||
|
||||
<https://www.youtube.com/watch?v=u1wfCnRINkE>
|
||||
|
||||
to one like:
|
||||
|
||||
<https://invidious.perennialte.ch/watch?v=u1wfCnRINkE>.
|
||||
|
||||
I can't do that
|
||||
directly with a Feedbin custom sharing service definition but it would be
|
||||
trivial to set up a little redirector application to do it. I even published [a
|
||||
video on building a very similar thing][url-shortener] last year. Alternatively
|
||||
I could install a [redirector browser
|
||||
plugin](https://docs.invidious.io/redirector/), although that would require set
|
||||
up on each of the computers and OS installs I use so I prefer the former
|
||||
option.
|
||||
|
||||
### Comments
|
||||
|
||||
* [Fediverse](https://mastodon.decentralised.social/@wezm/112391817575822540)
|
||||
* [Lobsters](https://lobste.rs/s/n3dnfa/exporting_youtube_subscriptions_opml)
|
||||
<!-- * [Hacker News](https://news.ycombinator.com/item?id=36742534) -->
|
||||
|
||||
|
||||
[url-shortener]: https://www.youtube.com/watch?v=d-tsfUVg4II
|
||||
[Invidious]: https://invidious.io/
|
||||
[Feedbin]: https://feedbin.com/
|
||||
[scraper]: https://github.com/causal-agent/scraper
|
||||
[repo]: https://forge.wezm.net/wezm/youtube-to-opml
|
||||
[NewPipe]: https://newpipe.net/
|
||||
[subscriptions]: https://www.youtube.com/feed/channels
|
||||
[jaq]: https://github.com/01mf02/jaq
|
||||
[jq]: https://jqlang.github.io/jq/
|
||||
[FeedMe]: https://play.google.com/store/apps/details?id=com.seazon.feedme
|
||||
[feedbin-sharing]: https://feedbin.com/help/sharing-read-it-later-services/
|
||||
[OpenGraph]: https://ogp.me/
|
||||
[feedbin-search]: https://feedbin.com/help/search-syntax/
|
||||
Loading…
Reference in a new issue